

AMD Instinct MI250 zwiększa wydajność sztucznej inteligencji dzięki PyTorch 2.0 i ROCm 5.4, zbliżając się do układów graficznych NVIDIA w LLM

Układy graficzne AMD Instinct, takie jak MI250, otrzymały znaczny wzrost wydajności sztucznej inteligencji, zbliżając je do chipów NVIDII.
We wpisie na blogu MosaicML, producent oprogramowania pokazał, w jaki sposób PyTorch 2.0 i ROCM 5.4 pomagają zwiększyć wydajność układów graficznych AMD Data Center, takich jak seria Instinct, bez konieczności wprowadzania jakichkolwiek zmian w kodzie. Producent oprogramowania oferuje ulepszone wsparcie dla treningu ML i LLM na szerokiej gamie rozwiązań NVIDIA i AMD obsługujących 16-bitową precyzję (FP16 / BF16). Ostatnie wersje pozwoliły MosaicML na uzyskanie jeszcze lepszej wydajności z akceleratorów AMD Instinct przy użyciu ich LLM Foundry Stack.
Poniżej przedstawiamy najważniejsze wyniki:
- Szkolenie LLM było stabilne. Przy użyciu naszego wysoce deterministycznego stosu treningowego LLM Foundry, trenowanie modelu MPT-1B LLM na AMD MI250 vs NVIDIA A100 dało niemal identyczne krzywe strat przy starcie z tego samego punktu kontrolnego. Byliśmy nawet w stanie przełączać się między AMD i NVIDIA w jednym przebiegu treningowym!
- Wydajność była konkurencyjna w stosunku do istniejących systemów A100. Przeanalizowaliśmy przepustowość trenowania modeli MPT z parametrami od 1B do 13B i stwierdziliśmy, że przepustowość MI250 w przeliczeniu na procesor graficzny mieściła się w granicach 80% przepustowości A100-40GB i w granicach 73% przepustowości A100-80GB. Spodziewamy się, że różnica ta będzie się zmniejszać w miarę ulepszania oprogramowania AMD.
- Wszystko po prostu działa. Nie były potrzebne żadne zmiany w kodzie.
Podczas gdy układ GPU AMD Instinct MI250 oferował niewielką przewagę nad układami graficznymi NVIDIA A100 pod względem liczby FLOPów FP16 (bez uwzględnienia sparsity), należy zauważyć, że MI250 może skalować się tylko do 4 akceleratorów, podczas gdy układy GPU NVIDIA A100 mogą skalować się do 8 układów graficznych w pojedynczym systemie.
Przyglądając się bliżej, zarówno sprzęt AMD, jak i NVIDIA były w stanie z łatwością uruchomić obciążenia treningowe AI z LLM foundry. Wydajność została oceniona w dwóch obciążeniach treningowych, pierwszym była ogólna przepustowość (Tokeny/Sec/GPU), a drugim ogólna wydajność (TFLOP/Sec/GPU).
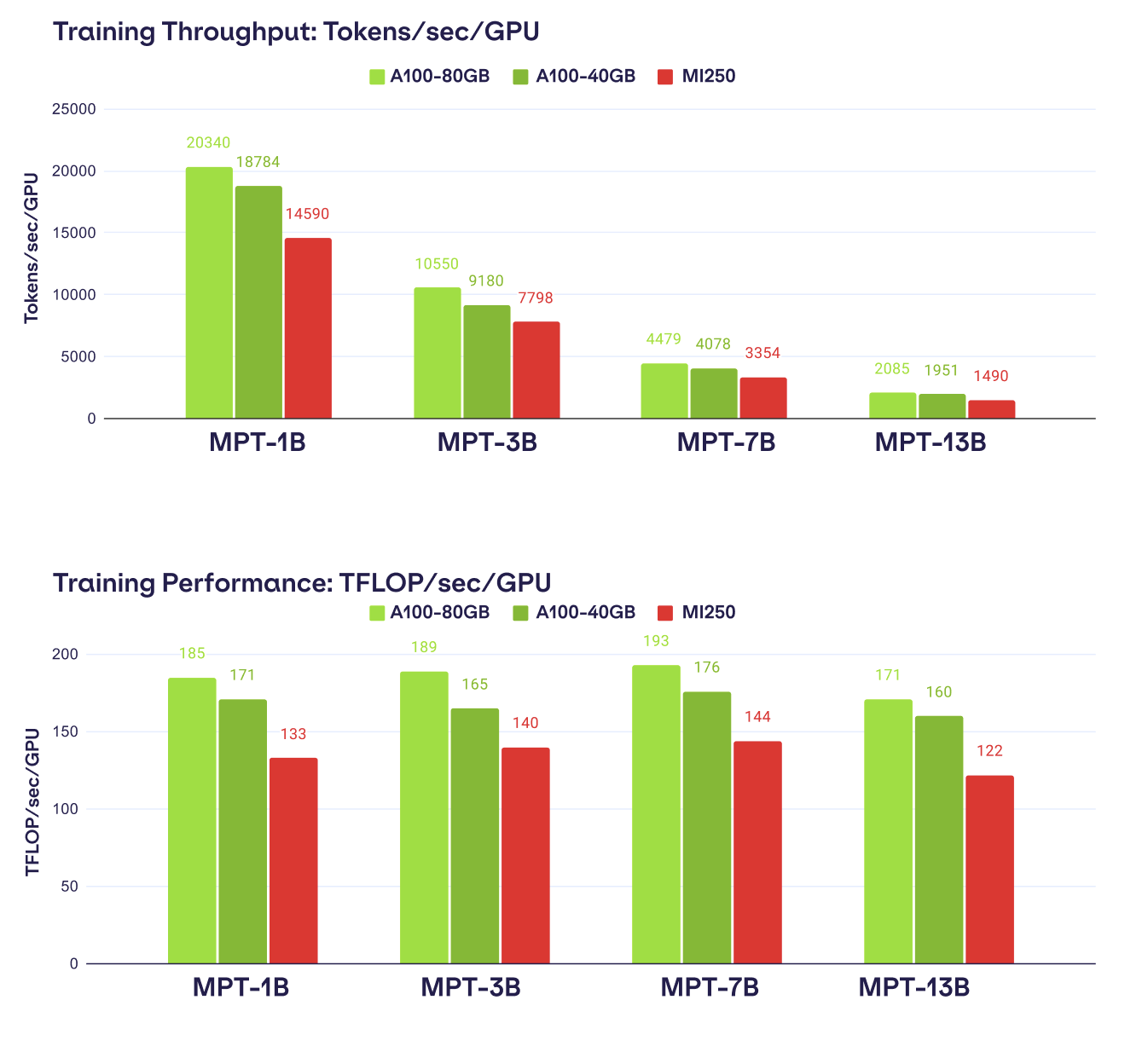
Przepustowość treningu AI została przeprowadzona na szeregu modeli o parametrach od 1 miliarda do 13 miliardów. Testy wykazały, że AMD Instinct MI250 zapewnił 80% wydajności NVIDIA A100 40 GB i 73% wydajności wariantu 80 GB. NVIDIA utrzymała pozycję lidera we wszystkich testach porównawczych, ale należy wspomnieć, że mieli oni również dwa razy więcej układów graficznych uruchomionych w testach. Co więcej, wspomniano, że w przyszłości oczekuje się dalszych ulepszeń po stronie treningowej dla akceleratorów AMD Instinct.
AMD już przygotowuje swoje akceleratory Instinct MI300 nowej generacji dla obciążeń HPC i AI. Firma zademonstrowała, jak układ poradził sobie z modelem LLM o 40 miliardach parametrów na jednym rozwiązaniu. MI300 będzie również skalowany w konfiguracjach do 8 GPU i APU. Chip będzie konkurował z NVIDIA H100 i wszystkim, nad czym pracuje zespół zielonych, a co ma zostać wydane w nadchodzącym roku. MI300 zaoferuje największą pojemność pamięci na jakimkolwiek GPU z 192 GB HBM3 i znacznie wyższą przepustowością niż rozwiązanie NVIDII. Ciekawie będzie zobaczyć, czy te postępy w oprogramowaniu na froncie AMD wystarczą, aby przejąć ponad 90% udziału w rynku, który NVIDIA zdobyła w obszarze sztucznej inteligencji.
Najnowszy numer




















Najnowszy numer